Abstract
Appearance editing according to user needs is a pivotal task in video editing. Existing text-guided methods often lead to ambiguities regarding user intentions and restrict fine-grained control over editing specific aspects of objects. To overcome these limitations, this paper introduces a novel approach named Zero-to-Hero, which focuses on reference-based video editing that disentangles the editing process into two distinct problems. It achieves this by first editing an anchor frame to satisfy user requirements as a reference image and then consistently propagating its appearance across other frames. We leverage correspondence within the original frames to guide the attention mechanism, which is more robust than previously proposed optical flow or temporal modules in memory-friendly video generative models, especially when dealing with objects exhibiting large motions. It offers a solid ZERO-shot initialization that ensures both accuracy and temporal consistency. However, intervention in the attention mechanism results in compounded imaging degradation with over-saturated colors and unknown blurring issues. Starting from Zero-Stage, our HERO-Stage Holistically learns a conditional generative model for vidEo RestOration. To accurately evaluate the consistency of the appearance, we construct a set of videos with multiple appearances using Blender, enabling a fine-grained and deterministic evaluation. Our method outperforms the best-performing baseline with a PSNR improvement of 2.6 dB.
Method
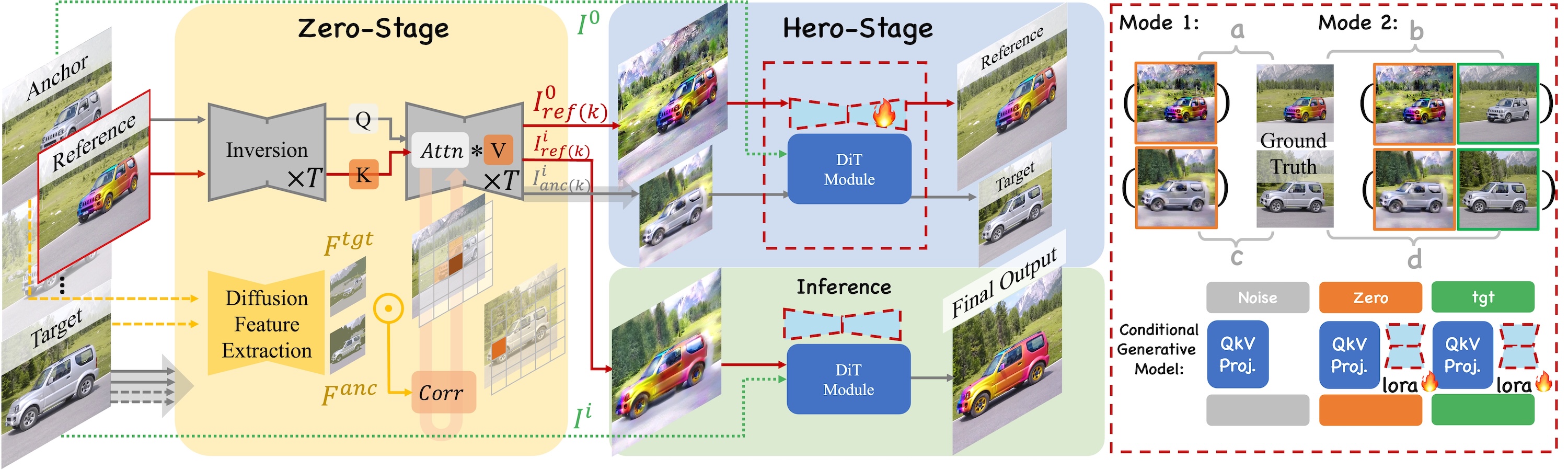
Our framework. Zero-Stage: Correspondences (Corr) estimated from the anchor and target frames are utilized to guide Cross-image Attention (Attn) between the reference and anchor frames, enabling accurate appearance transfer in a zero-shot manner. Hero-Stage: We learn a conditional generative model by incorporating LoRA to process conditional tokens. There are two modes of condition injection: one condition with one LoRA (Mode 1) and two conditions with two independent LoRAs (Mode 2). Four pairs of images serve as potential training data, from a to d.